
XenonPyとPyTorchを用いた物性値予測モデルの学習
Last Update:2021/12/09
(株式会社アカデメイア)
1. はじめに
XenonPyは機械学習を用いて物質探索を行うためのPythonツールです。ここでは、最新のMateriApps3.2環境でXenonPy実行環境を整え、PyTorchを用いた物性値の予測モデルの学習を行います。
2. インストール方法
ここではMateriApps LIVE! 3.2の環境でのXenonPyのインストール方法について記します。基本的にインストール方法は下記レビューに従っていますが、新しいMateriApps LIVE!環境とXenonPyのバージョンを用いる事による変更点がいくつかあります。
「XenonPyまでの長く曲がりくねった道」
https://ma.issp.u-tokyo.ac.jp/app-post/2351
上記のリンク先のインストール方法から以下の点をご変更下さい。
- Python3のバージョンは3.5でなく3.7なので”ディレクトリ等の準備”の部分を以下の通り変更して下さい
(変更前) sudo mkdir -p /usr/local/lib/python3.5 sudo ln -s python3.5 /usr/local/lib/python3 (変更後) sudo mkdir -p /usr/local/lib/python3.7 sudo ln -s python3.7 /usr/local/lib/python3
- numpyは1.13.3ではなく1.16.5以上にアップデートする必要があります。
- MateriApps LIVE! ver. 3.2ではCythonは既にインストールされていますので、”Cythonのインストール”を行う必要はありません。
- インストールするRDkitのバージョンを2019_09_3から2020_09_4に変更して下さい
- RDkitのインストール前に以下のパッケージを(リンク先のパッケージに加えて)インストールしておく必要があります。
sudo apt install -y python3-setuptools zlib1g-dev libfreetype6-dev
- pymatgenの最新版ではインポート時にエラーが生じるので、xenonpyをインストールする前にversion2021.3.3をインストールして下さい。
sudo pip3 install --no-cache-dir pymatgen==2021.3.3
- ipywidgetsをインストールして下さい
sudo pip3 install ipywidgets
また、上記のインストール後に、以下を実行して環境変数を設定しておく必要があります。
export LD_LIBRARY_PATH=/usr/local/lib
以上で、RDkitおよびXenonPyの実行環境の構築は終了です。
3. データの準備
ここからは、XenonPyとPytorchを用いた学習を実行します。
まず、Materials Projectのサイトからサンプルデータをダウンロードします。
方法については、「XenonPyまでの長く曲がりくねった道」の「Materials API のキー取得」をご参照下さい。
APIを取得した後に、以下の通り実行して下さい。
user@malive:~$ python3
Python 3.7.3 (default, Jul 25 2020, 13:03:44)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from xenonpy.datatools import preset
>>> preset.build('mp_samples', api_key='your api key') # ‘your api key’には前述のMaterials APIを入力して下さい。
上記実行後、サンプルデータが~/.xenonpy/userdataにダウンロードされます。
詳しくはXenonPyのページをご参照下さい。
https://xenonpy.readthedocs.io/en/latest/tutorial.html
次に、XenonPyのJupyter-Notebookサンプルを取得します。
mkdir ~/XenonPy cd ~/XenonPy wget -O - https://github.com/yoshida-lab/XenonPy/archive/master.tar.gz | tar zxf - --strip-components=2 XenonPy-master/samples
上記でsamplesファイルがダウンロードされます。
4. 学習の実行
ここまででXenonPyとJupyter Notebookを用いて学習を実行するための環境が整いました。
jupyter-notebook
とすると、ブラウザが立ち上がり、Jupyter Notebookが使用出来るようになります。
ここでは、random_nn_model_and_training.ipynbを実行してみます。全体については、下記のXenonPyのチュートリアルページを見ていただくとして、ここでは下記チュートリアル中のIn[13]〜In[22]で実施されているPyTorchによるニューラルネットワークモデルの学習と予測について解説します。
「Random NN models」
https://xenonpy.readthedocs.io/en/latest/tutorials/4-random_nn_model_and_training.html
上記と同様の内容がXenonPyのGitHubリポジトリ中にもあります。
https://github.com/yoshida-lab/XenonPy/blob/master/samples/random_nn_model_and_training.ipynb
まず、データセットを用意します。In[14]に以下のような記述があります。
prop = data[data.volume <= 2500]['volume'].to_frame() # reshape to 2-D desc = Compositions(featurizers='classic').transform(data.loc[prop.index]['composition'])
ここでは、propがvolumeデータ、descが原子番号、原子半径等の記述子となっています。問題設定としては、descのデータを用いてpropの値を推定する、というものになります。
まずこのpropとdescを訓練用データ、評価用データに分割します。In[17]に下記のような記述があります。
sp = Splitter(prop.shape[0]) x_train, x_val, y_train, y_val = sp.split(desc, prop)
上記でprop, descのデータを訓練用:評価用 = 8:2に分割しました。
x_trainとy_trainを用いて学習を実行し、x_val, y_valを用いて学習を評価します。
次に、学習モデルを定義します。まず、以下のようにニューラルネットワークモデルを作成します。(In[18])
model = SequentialLinear(290, 1, h_neurons=(0.8, 0.6, 0.4, 0.2))
これは、入力の特徴量の次元が290、出力次元が1、途中の各層で出力される特徴量の次元が290の0.8倍、0.6倍、0.4倍、0.2倍である事を示しています。
詳しい情報はOut[18]に記載されています。
SequentialLinear(
(layer_0): LinearLayer(
(linear): Linear(in_features=290, out_features=232, bias=True)
(dropout): Dropout(p=0.1)
(normalizer): BatchNorm1d(232, eps=0.1, momentum=0.1, affine=True, track_running_stats=True)
(activation): ReLU()
)
(layer_1): LinearLayer(
(linear): Linear(in_features=232, out_features=174, bias=True)
(dropout): Dropout(p=0.1)
(normalizer): BatchNorm1d(174, eps=0.1, momentum=0.1, affine=True, track_running_stats=True)
(activation): ReLU()
)
(layer_2): LinearLayer(
(linear): Linear(in_features=174, out_features=116, bias=True)
(dropout): Dropout(p=0.1)
(normalizer): BatchNorm1d(116, eps=0.1, momentum=0.1, affine=True, track_running_stats=True)
(activation): ReLU()
)
(layer_3): LinearLayer(
(linear): Linear(in_features=116, out_features=58, bias=True)
(dropout): Dropout(p=0.1)
(normalizer): BatchNorm1d(58, eps=0.1, momentum=0.1, affine=True, track_running_stats=True)
(activation): ReLU()
)
(output): Linear(in_features=58, out_features=1, bias=True)
)
次に、損失関数、最適化手法を設定します。In[19]に以下のように記載されています。
trainer = Trainer(
model=model,
optimizer=Adam(lr=0.01),
loss_func=MSELoss()
)
ここでは、モデルとしてIn[18]で定義されたモデル、最適化手法としてAdam法(学習率0.01)、損失関数として平均二乗誤差を用いています。
ここまでで、モデルの設定が終了し、学習が行えるようになりました。学習はIn[20]で実行しています。
Jupyter Notebookでtrainer.fitを実行すると、上記のようにプログレスバーが表示され、進行状況が分かります。ここでは、400エポックの学習を大体9秒程度で実行できます。
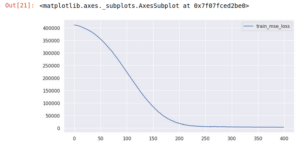
学習が進んでいるかについて、損失関数をプロットする事で確認する事が出来ます。In[21]で損失関数をプロットしています。
_, ax = plt.subplots(figsize=(10, 5), dpi=100) trainer.training_info.tail(3) trainer.training_info.plot(y=['train_mse_loss'], ax=ax)
上記実行により以下のようにグラフが表示されます。学習が進むにつれ損失関数が減少している事が見てとれます。
モデル学習が終了したので、最後に学習に用いなかったx_valデータを用いて汎化性能を見る事とします。これについてはIn[22]で実行しています。
y_pred = trainer.predict(x_in=torch.tensor(x_val.values, dtype=torch.float)).detach().numpy().flatten() y_true = y_val.values.flatten() y_fit_pred = trainer.predict(x_in=torch.tensor(x_train.values, dtype=torch.float)).detach().numpy().flatten() y_fit_true = y_train.values.flatten() draw(y_true, y_pred, y_fit_true, y_fit_pred, prop_name='Volume ($\AA^3$)')
上記で、y_predがモデルにx_valを入れて予測される体積値、y_trueがデータにある実際の体積値、y_fit_predとy_fit_trueはx_trainからの予測値と実測値となります。
上記では、draw関数を用いてこれらをまとめてプロットしています。この関数は他のJupyter Notebookで定義されているプロット用の関数となっています。同じディレクトリにあるtools.ipynbをご確認下さい。
XenonPyのGitHubリポジトリでは下記リンク先にあります。
https://github.com/yoshida-lab/XenonPy/blob/master/samples/tools.ipynb
出力されるグラフは以下のようになります。
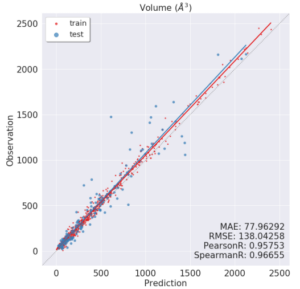
上記では、横軸が体積の予測値、縦軸が実測値を取っており、赤い点が訓練データ、青い点がテストデータとなっています。赤い直線、青い直線は予測値vs実測値をフィッティングした線となっています。
上記結果より、全体的に予測値は実際の体積を過小評価している傾向がある事、体積の小さい領域と比べ、体積の大きい領域(1000〜1500Å3あたり)では予測値と実測値の差が大きくなりがちである事が見てとれます。
ここまでで、データの準備、モデルの作成、学習、評価の過程を一通り実行する事が出来ました。
5. 終わりに
今回はXenonPyとPyTorchを用いた物質系の機械学習を一通り実行してみました。環境構築さえ出来てしまえばJupyter Notebookを用いて内容を確認しながらインタラクティブにデータの準備、学習、結果の確認を行う事が出来ます。
ただ、最新のMateriApps LIVE!環境で環境構築をするのが一筋縄ではいかなかった印象です。MateriApps LIVE!のバージョンやXenonPy, RDKitのバージョンが更新されると、そちらに合わせてLinuxのライブラリやPythonパッケージのインストール内容も変える必要があります。
もう少しお手軽にXenonPyを試したい、という方にはXenonPyから提供されている公式のDockerイメージを用いる方法があります。詳しくは下記のXenonPyサイトをご参照下さい。
https://xenonpy.readthedocs.io/en/latest/installation.html#using-docker