
sekirei (ISSP System B) 上で mptensor (v0.2) を使ってみた(2020.02.01)
Last Update:2021/12/09
はじめに
最近テンソル表現に基づく計算がはやりです.よく知られているのは機械学習関係のアプリケーション開発に使われるツールボックスである TensorFlow です.マーケットははるかに小さいですが,物性科学計算でもテンソル表現を使う計算手法がテンソルネットワーク法として,また,数値計算手法としてだけでなくトポロジカル現象を理解するツールとしても注目されています.データ科学の分野でも,大規模データをテンソルネットワークの形に表現することによるデータ圧縮や特徴抽出の試みがされています.小規模なテンソル計算であれば,numpy の tensordot や linalg.svd 関数が便利ですが,論文クオリティの大規模計算をするには,mpi 並列にも対応して,かつ python のテンソル関連関数のように使い勝手の良いライブラリが欲しくなります.そういうわけで,縮約や分割(特異値分解)などのテンソル計算を多用する並列計算機用プログラム開発のために東大物性研の森田悟史さんがmptensorを開発しています.まだバージョン 0.2 なので,マニュアルやチュートリアルはあまり充実していないようですが,ミニ実行ファイルがパッケージに含まれているので,そのソースコードをみれば使い方は大体わかるでしょう.以下では,mptensor を使ったお試し計算を物性研スパコン sekirei 上で行ってみた結果をレポートします.
インストール
まず物性研のスパコン sekirei に mptensor v0.2 をインストールします.最初にソースコードを入手します.
$ git clone https://github.com/smorita/mptensor.git
これで手元にコピーできました.
$ mptensor> cd mptensor
で作業ディレクトリに入って,コンパイルの準備として Makefile.option を編集します.
$ mptensor> emacs Makefile.option
Makefile.option のなかでは,あらかじめ sekirei 用の設定も書かれているので,その部分こコメントアウトを外せばOKです.具体的には最初の(本当の)コメント文も含めて以下の4行です.
##### ISSP System B (sekirei) ##### CXX = mpicxx CXXFLAGS = -O3 -xCORE-AVX2 -qopenmp -parallel LDFLAGS = -lmkl_scalapack_lp64 -lmkl_blacs_sgimpt_lp64 -mkl=parallel -lmpi
これでライブラリ src/libmptensor.a を生成する準備ができたので make します.
$ mptensor> make
make -C src make[1]: Entering directory '/home/k0148/k014800/test_mptensor/mptensor/src' <中略> ar: creating libmptensor.a a - mptensor/tensor.o a - mptensor/index.o a - mptensor/scalapack/matrix_scalapack.o a - mptensor/scalapack/blacsgrid.o a - mptensor/rsvd.o a - mptensor/lapack/matrix_lapack.o a - mptensor/mpi_wrapper.o make[1]: Leaving directory '/home/kxxxx/kxxxxxx/mptensor/src'
これで,うまくsrc/libmptensor.aができました.
テスト用実行ファイルの作成
次にテスト用実行ファイル tensor_test.out を作ります.
$ mptensor> cd tests
このディレクトリの Makefile を編集して,blas 関係のライブラリの場所をしています.
$ mptensor/tests> emacs Makefile
具体的には以下の行を始めのほうに加えます.
LDFLAGS = -lmkl_scalapack_lp64 -lmkl_blacs_sgimpt_lp64 -mkl=parallel -lmpi
make します.
$ mptensor/tests> make
これで,tensor_test.out ができました.
テストプログラム実行用バッチスクリプトの作成
今度は,tensor_test.out を sekirei 上で mpi 実行するためのシェルスクリプト run.sh を作ります.run.sh の中身は以下の通りです.
#!/bin/bash #QSUB -queue i18cpu #QSUB -node 1 #QSUB -omp 1 #QSUB -place pack #QSUB -over false #PBS -l walltime=00:10:00 #PBS -N mptensor HDIR=/home/kxxxx/kxxxxxx/test_mptensor/mptensor export HDIR PATH=$HDIR/src:$PATH PATH=$HDIR/tests:$PATH export PATH mpijob tensor_test.out
tensor_test.out の実行
以下のようにバッチスクリプトをジョブキューに投入します.
$ mptensor> qsub run.sh (ジョブの投入) $ mptensor> qstat -u kxxxxx
ジョブが終了するまでしばらく待ちます.インタラクティブキューに投げたので,比較的短時間で終了するはずです.何度か qstat で様子を確認しながら待っていると,終了して出力ファイル mptensor.oxxxxxxx ができているはずなので,中身を確認してみます.
$ mptensor> cat mptensor.oxxxxxxx <前略> ======================================== Contract <complex> ( A[N0, N1, N0, N2], Axes(0), Axes(2) ) [N0, N1, N0, N2] = [10, 11, 10, 12] Error= 1.77636e-15 Time= 0.000138 [sec] Time(check)= 0.000156 [sec] ---------------------------------------- A: Tensor: shape= [10, 11, 10, 12] upper_rank= 2 axes_map= [0, 1, 2, 3] Matrix: prow= 0 pcol= 0 local_size= 960 lld(locr)= 30 locc= 32 ========================================
どうやらうまく実行できたようです.正しくインストールされていることが確認できました.
テンソル繰り込み群(TRG)法によるイジングモデルの計算
インストールテストだけではやや物足りないので,mptensor のもともとの目的である物理計算をしてみました.テンソルネットワーク法による計算にもいろいろありますが,examples のなかにテンソル繰り込み群(TRG)法による2次元イジングモデルの自由エネルギーの計算プログラムが含まれていますから,これを実行してちょうど臨界温度にある2次元イジングモデルの自由エネルギーを計算してみます.
実行ファイル trg.out の生成
tests のときと同様に,作業ディレクトリに移って Makefile を編集して,ライブラリの場所を指定します.
$ mptensor> cd examples/Ising_2D> $ mptensor/examples/Ising_2D> emacs Makefile
以下の行を始めのほうに加えます.
LDFLAGS = -lmkl_scalapack_lp64 -lmkl_blacs_sgimpt_lp64 -mkl=parallel -lmpi
あとは make するだけです.
$ mptensor/examples/Ising_2D > make
確認すると2つ実行ファイルができています.
$ mptensor/examples/Ising_2D > ls *.out hotrg.out trg.out #2種類の繰り込み群の実行ファイルができた.
trg.out も hotrg.out も,ともにテンソルネットワーク表現に
基づく繰り込み群の計算プログラムですが,繰り込み変換の仕方が
かなり違います.mptensor はテンソルの縮約や分割などベーシックな
操作のためのライブラリなので様々な計算方式に利用できます.
以下では trg.out の実行を試します.
テンソル繰り込み群計算プログラム trg.out の実行
tests のときと同様にまず,バッチスクリプトを用意します.中身は tests のときとほとんど同じです.
$ mptensor> emacs run.sh
上の「テスト」のところで作ったスクリプト “run.sh” を “run_trg.sh” としてコピーして,
以下の行を path 設定の部分に加えます.
PATH=$HDIR/examples:$PATH
また最後の実行文を以下に置き換えます.
mpijob trg.out
run_trg.sh ができたら,これをバッチキューに投入します.
$ mptensor> qsub run_trg.sh
実行終了したら,結果を確認します.
$ mptensor> cat mptensor.oxxxxxxx # 実行結果の確認 <前略> ##### parameters ##### # T= 2.269185314 #温度はちょうど臨界温度に設定 # chi= 8 #ボンド次元は8 # f_exact= -2.109651145 #自由エネルギーの厳密値 ##### keys ##### #次のoutputセクションの各コラムの意味 # 1: step #繰り込み群のステップ数 # 2: N_spin #繰り込まれた1サイトに対応する(元の)スピン数 # 3: free energy (f) #繰り込まれた1サイト系の自由エネルギー # 4: relative error ((f-f_exact)/|f_exact|) ##### output ##### 0 1.000000e+00 -3.5728794027e+00 -6.9358778196e-01 1 2.000000e+00 -2.8193568384e+00 -3.3640902936e-01 2 4.000000e+00 -2.4859076215e+00 -1.7835009254e-01 3 8.000000e+00 -2.2892976961e+00 -8.5154624728e-02 4 1.600000e+01 -2.2011430750e+00 -4.3368274725e-02 5 3.200000e+01 -2.1548523417e+00 -2.1425910748e-02 6 6.400000e+01 -2.1323109230e+00 -1.0741007337e-02 7 1.280000e+02 -2.1209406219e+00 -5.3513479261e-03 8 2.560000e+02 -2.1152643697e+00 -2.6607361809e-03 9 5.120000e+02 -2.1124118689e+00 -1.3086164761e-03 10 1.024000e+03 -2.1109761387e+00 -6.2806310704e-04 11 2.048000e+03 -2.1102506060e+00 -2.8415188545e-04 12 4.096000e+03 -2.1098827582e+00 -1.0978760762e-04 13 8.192000e+03 -2.1096958939e+00 -2.1211683550e-05 14 1.638400e+04 -2.1096011032e+00 2.3720238913e-05 15 3.276800e+04 -2.1095532720e+00 4.6392793419e-05 16 6.553600e+04 -2.1095292808e+00 5.7764933470e-05
自由エネルギーが4桁以上の精度で計算できました!
どこまでできるか
テンソルネットワークの計算で精度を決めるのはテンソルの各インデックスの次元(ボンド次元)です.これを変えて,どの程度の規模の計算までできるのかを調べてみます.trg.cc の中身をみると,trg.out が,ボンド次元(chi),繰り込み群変換の実行回数(nstep),温度(T)の3つをコマンドライン引数としてとることが分かります.なので,上でつかっていたものを少し書き換えて以下のようなシェルスクリプトを作りました.
#!/bin/bash
#QSUB -queue i18cpu
#QSUB -node 16
#QSUB -omp 1
#QSUB -place pack
#QSUB -over false
#PBS -l walltime=00:10:00
#PBS -N mptensor
#PBS -o mptensor.o.16node
#PBS -e mptensor.e.16node
HDIR=/home/kxxxx/kxxxxxx/test_mptensor/mptensor
PATH=$HDIR/examples/Ising_2D:$HDIR/tests:$HDIR/src:$PATH
export PATH
nstep=16
chilist=( "6" "12" "24" "48" "96" )
for chi in "${chilist[@]}"; do
echo >&2
command="time mpijob -np 384 trg.out ${chi} ${nstep}"
echo $command >&2
$command
done
これで,16ノード(394プロセス)の mpi 並列計算で,ボンド次元が 6, 12, 24, 48, 96 のそれぞれの場合にかかった計算時間がエラー出力(mptensor.e.16node)にでてくるはずです.実行結果は
$ mptensor> more mptensor.e.16node <中略> time mpijob -np 384 trg.out 96 16 Usage: trg.out chi step T Warning: Assuming T = T_c 0.04user 0.02system 3:27.84elapsed 0%CPU (0avgtext+0avgdata 2100maxresident)k 0inputs+0outputs (0major+13450minor)pagefaults 0swaps
となって,一番規模の大きなボンド次元 96 の計算が約3分半で終わっています.以前,手元のPCで,あまり計算効率に気を使わない自前プログラムで同様の計算をしたときには,たしかボンド次元20くらいが限界だったので,高効率なソフトと高性能なハードのありがたみがよくわかります.
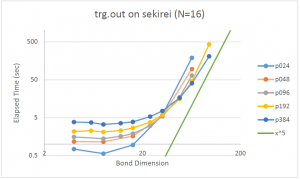
最後にいろいろなボンド次元とプロセス数の組み合わせで時間を測った結果をグラフにまとめておきます.凡例で,”p024″ はプロセス数が 24 の計算であることを意味します.計算規模が小さいときにはプロセス数が増加するとむしろ計算時間が増えてしまいますが,大きな計算ほど並列化が有効に働いていることがわかります.また,図中で,緑の直線はボンド次元の5乗に比例する直線で,これは trg アルゴリズムの漸近的な理想曲線です.計算規模が大きくなると,この直線の傾きに近づいていっているように見えるところから,少なくとも大きな無駄はないプログラムになっていることが分かります.
おわりに
パッケージされている trg や hotrg は2次元イジングモデル用ですが,正方格子上の統計力学モデルであれば,それほど変更せずに利用できそうです.mptensor はテンソルの部分縮約や特異値分解のためのツールなので,いろいろなテンソルネットワーク計算に利用できます.パッケージされているのは,trg や hotrg など,繰り込み変換を数値的に行う例ですが,mptensor は虚数時間発展や変分原理による量子系の基底状態計算などにも応用され,TeNeS として公開されているので,そちらも参照してください.